Value Alignment as a Path to AI Beneficence and Human Learning
By George Gantz, for Long Now Boston, October 2, 2018
The long-term future of the human race may well be determined in this century by Artificial Intelligence (AI). According to Richard Mallah, Director of AI Projects with the Future of Life Institute (FLI), the median view among AI researchers is that human-level General Intelligence (AGI) will be achieved by mid-century. Once that goal has been reached, many expect that AGI agents will be able to use their intelligence to improve AI functionality at an accelerating rate, quickly becoming Artificial Super-Intelligence (ASI) with capabilities far beyond those of humans.

The Knife Edge of Value Alignment
In the ideal, AGI and ASI will bring immense benefits to the human race and the world we live in. Human toil, deprivation and suffering could be virtually eliminated and humanity freed to pursue self-fulfilling interests and passions without worldly concerns. Yet this future could go badly wrong. Lucas Perry, Project Coordinator for FLI, described a worst-case scenario as a self-directed malevolent ASI that vastly increases human suffering or extinguishes the human race entirely to suit its own purposes.
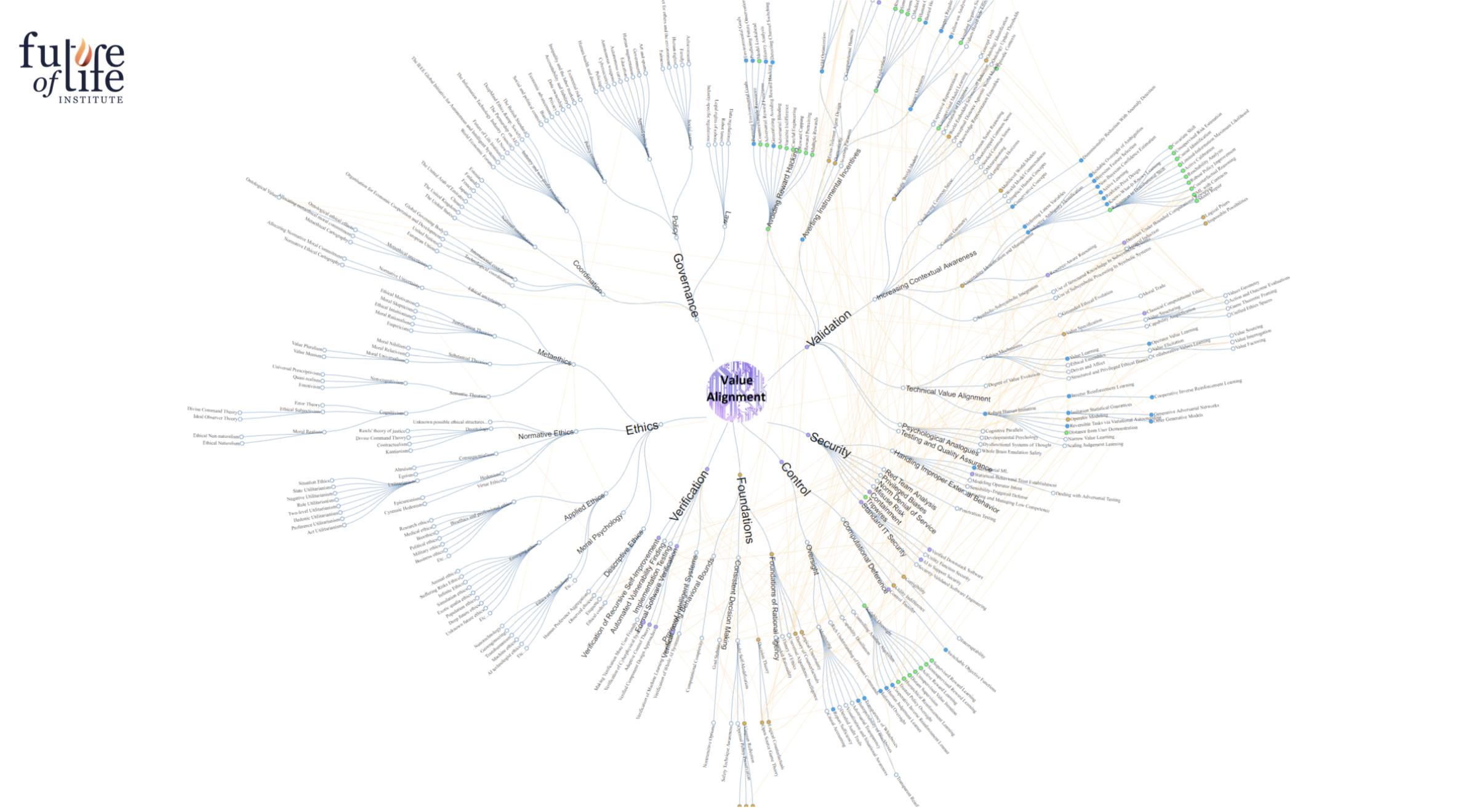
As Richard and Lucas explained to a packed Long Now Boston audience at the Café ArtSience on Monday October 1st, the factors that will determine which future we inhabit can be characterized collectively as the value alignment problem. AI agents will be able to pursue goals that may be disengaged from what we value. Seeking to ensure those agents use their intelligence in a beneficial manner invokes a complex array of technical, cognitive and philosophical issues. FLI’s Value Alignment Map (see Figure) captures that complexity and serves as a tool for inventorying research that is being done or that should be done. Its seven main branches include Governance, Validation, Security, Control, Foundations, Verifications and Ethics.
Slippery Slopes in Programming AI
Among the many interesting and challenging problems being encountered in AI programming are convergent instrumental goals and reward hacking. An autonomous intelligent system with capacities for planning and learning may be given a fundamental end goal, but as it learns how to achieve that goal it will also develop a set of instrumental goals helpful to achieving the end goal. These instrumental goals, for example relating to self-preservation, or accumulation of information or resources, can diverge from human values and may result in negative consequences. For example, an AI system, such as the “paperclip maximizer” theorized by Nick Bostrom, might learn that human bodies are a great source of raw materials. An ASI developing an instrumental goal of harvesting human bodies would have disastrous implications.
Reward hacking occurs when an AI is able to achieve its end-goal with behaviors the programmer did not intend. For example, a robot taught to clean a house could learn to be more successful as a cleaner by first pouring dirt on the floor. As AI systems become more complex and more autonomous from their programmers, guarding against value misalignment from instrumental goals or reward hacking becomes more critical and vastly more challenging.
AI Ethics
Fundamental to the programming of AI systems for beneficence is the need to assure compliance with some level of ethical standards of behavior. The deontological or rule-based approach, such as Asimov’s Laws of Robotics (formulated more than 50 years ago), yields inconsistencies and loopholes and results in an unworkably complex layering of do’s and don’ts. Teaching an AI agent to mimic or follow human ethical norms is one approach, but it creates other problems. Not all AI programmers or owners are going to have particularly laudable ethical standards. If you ask AIs to learn ethical norms from a broader human population, this is going to expose the AI to conflicts and biases that humans have been unable to resolve. The Microsoft chatbot Tay was tasked to behave like a 14 year-old girl and pick up cultural cues from twitter interactions with humans – within a day she was spewing racist and misogynistic rant.
One hope is that we can ask advanced AI to do their own ethical reasoning, something they may be able to do more systematically than emotion-laden humans. Lucas pointed out, however, that this leads us quickly into a sea of questions about the ethical frame of reference and the meta-ethical epistemology that need to be instantiated in an AI system. These are questions philosophers have argued about for thousands of years. Yet there is a difference. Now, in the 21stcentury, we are on deadline. AGI and ASI may be only decades away.
Value Alignment Lessons from Value Alignment
The biggest take-away from the Long Now Boston AI conversation may be this. AI Value Alignment is an opportunity to examine the foundations of decision-making including the role of ethics. This can be done now, in a simulated environment that does not yet influence the human world. In addition, AI systems themselves may assist us in evaluating the consequential outcomes of alternative ethical choices. What we learn about AI decision-making and ethics may yield new knowledge that can be applied to the non-simulated value alignment problems of the human world. In the quest for optimal, ethically-guided AI, perhaps we will find practical ethical insights applicable to the human race.
Will AI teach us to be better humans?

___________________________________________________________________
Richard Mallah is the Director of AI Projects with Future of Life Institute (FLI).Richard has over fifteen years experience leading AI research and AI product teams in industry, and he understand the tradeoffs in AI product lifecycle stages. Richard was the lead author of FLI’s landmark Landscape of Technical AI Safety Research, and he has given dozens of invited talks on safety, ethics, robustness, and beneficence of advanced AI. He has chaired committees on autonomous weapons and AGI safety for IEEE’s Global Initiative on the Ethics of Autonomous and Intelligent Systems. He holds a degree in computer science, AI, and machine learning from Columbia University.
Lucas Perry is a Project Coordinator for the Future of Life Institute and works to support existential risk mitigation efforts. Lucas was an organizer of the Beneficial AI 2017 conference and has worked on nuclear weapons divestment. He also hosts a fascinating podcast on AI safety and value alignment. Lucas studied philosophy at Boston College and has been working in AI safety and existential risk ever since. He has also studied at a Buddhist monastery in Nepal.
__________________________________________________________________
Long Now Boston is a 501(c)(3) non-profit organization that is independent from but philosophically aligned with the Long Now Foundation. Long Now Boston provides a forum for discussing, investigating and engaging in issues that have long-term implications for our global cultures. Long Now Boston hosts a monthly Community Conversation series in Cambridge, MA. Please sign up to the Long Now Boston Meetup Group for notices.